Blog & Business
(Pricing May Vary Depending on other conditions)
- Website & Server Maintenence
- On demand Customization
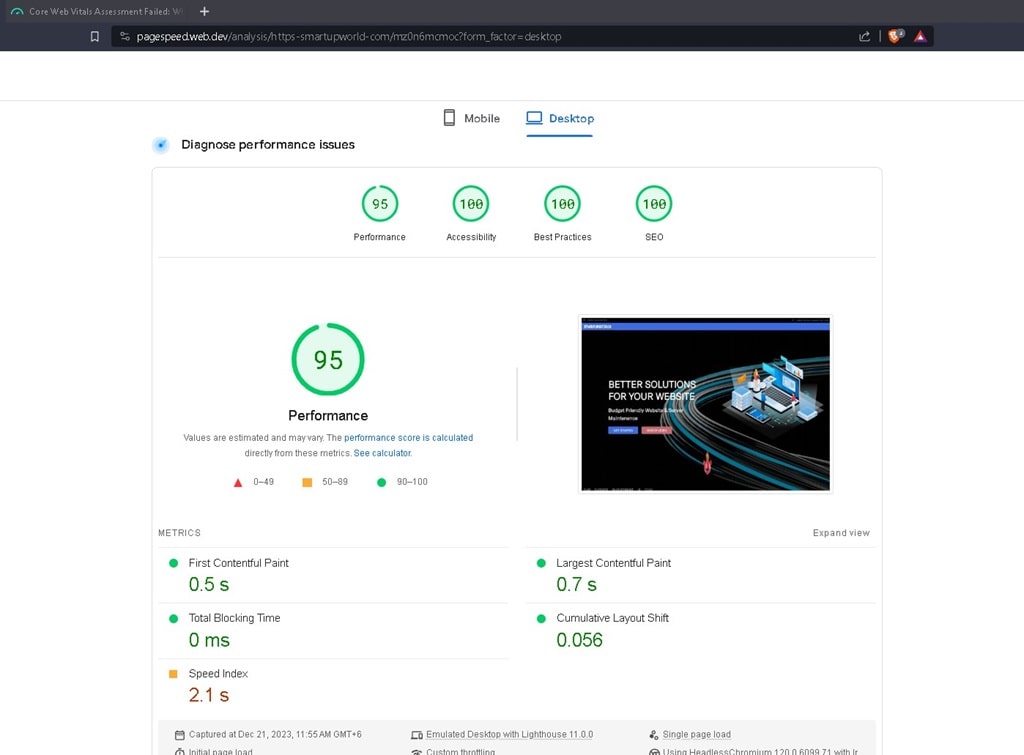
- Optimize website for Google page speed
- Content Compression
- Backup, migration to New Server
- SEO Service
WooCommerce
(Pricing May Vary Depending on other conditions)
- Website & server Maintenence
- Website customization
- Product Upload & Update
- Optimize website for Google page speed
- Anytime backup, migration
- SEO Service
Magento 2
(Pricing May Vary Depending on other conditions)
- Basic site & server Maintenence
- Product Upload & Update
- Basic site customization
- Optimize website for Google page speed
- Anytime backup, migration
- SEO Service